搞技术的对“高内聚,低耦合”这几个字应该很熟悉,这是程序设计的一个基本原则,无论对于分布式系统,有几个模块的单体程序,以及程序中具体的类、类中的方法,都可以拿来讲。这个原则本质上是“分治法”,将一个大问题分解为一个个的小问题,然后各个击破,整个问题就解决了。相信大家都很明白了,这里对这个原则就不过多解释了。
为什么要使用队列解耦?
让我们来看看不使用队列的情况下如何解耦的:
原始需求
假设有一个商城系统,业务上划分为用户、订单、财务、消息、仓储几个模块(模块的划分实际上也是解耦设计的重要部分,但非这篇文章的关注点),这几个模块是分布式部署的,用户在下单成功以后要做这么几件事:通知用户下单成功、通知仓库发货、给财务生成销售凭证,那么就要在下单成功的程序逻辑中去调用消息、仓储、财务模块的接口。

对于一个不经常变动、吞吐量也不是很大的系统,做到这一步也就可以了。
新增需求
假设商城最近又上线了一个优惠券的功能,需要在下单成功后给用户发优惠券,这时候怎么去做呢?一个很直接的想法就是修改下单成功的程序逻辑,增加一个调用发优惠券接口的处理。
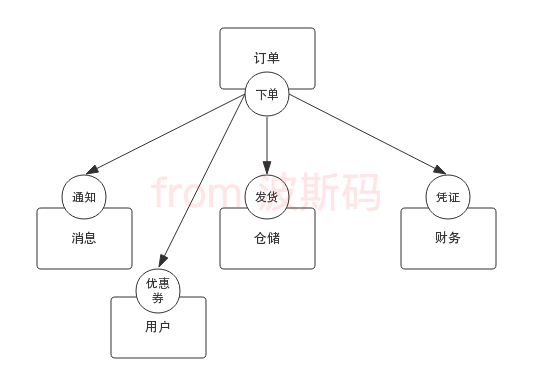
也能解决问题,但是这时候就要考虑下了,以后还会不会有别的需求?比如下单成功后给用户增加积分,给推荐的用户做返利等等。每次都修改下单的程序逻辑其实还是有一定技术风险的,能不能以后不改下单的代码也能扩展呢?
更好的扩展性
聪明的你一定想到了办法,用配置。
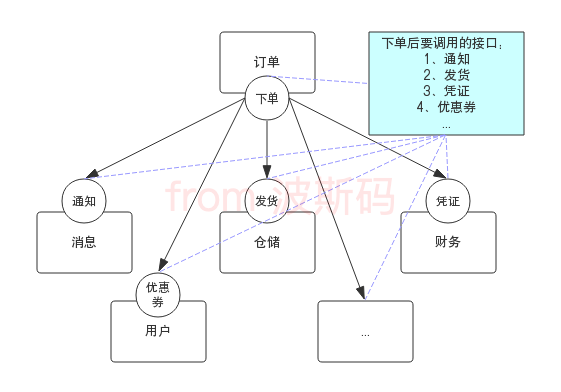
在订单模板中定义一个配置文件,所有需要下单成功后调用的接口地址都写到这里,下单的程序读取这个配置,一个个去调用。如果以后还有新增的下单后处理,在这里增加一行配置就行了,不用改下单的代码。
不过需要注意,每个接口接收的参数应该都是一样的,或者支持通过参数模板赋值(比如url:http://blog.bossma.cn/notice?orderId={OrderId}&Status={Status},其中{XXX}的内容会被实际值替换,不同的业务可以定义不同的url参数),否则还是要改代码。
还有没有问题
有一天你可能发现下单成功后,也通知用户了, 也发货了,但是没有生成财务凭证,然后到服务器上翻日志发现下单处理超时了,调用生成凭证接口没有成功,至于原因可能是网络抖动了,也可能是开发人员在升级程序…你想到了分布式事务,不过这个似乎不太好搞。你可能觉得也就是偶尔出现一次,手工处理下就好了。
然后双十一到了,超过平常10倍的用户来下单,用户可能发现提交订单一直在等待,等待,等…。至于原因也许就是上次发现的超时问题更严重了,本来处理很快的接口调用突然都慢了下来。
这时候你可能需要一个队列了。
使用队列
先来看看使用队列后是什么样的?
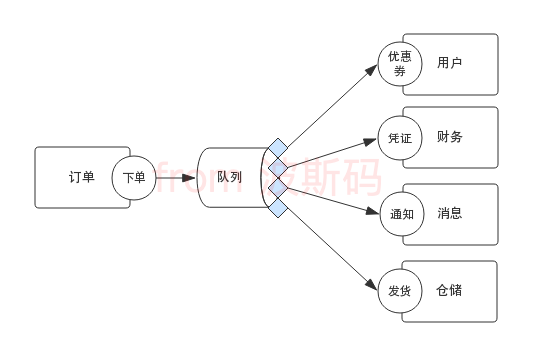
很明显只是在下单操作和下单后的操作中间增加了一个队列,下单成功后订单数据发送到队列,通知、发货、凭证等等操作从队列接收订单数据,然后按照自身的业务需求进行处理。
仔细想一下,其实是把上边提到的配置方式换成了队列方式,而且它们做的事以及做事方法本质是差不多的,接收数据,然后把数据分发给预先配置好的程序。形式上最大不同是队列从进程内独立了出来。
那么使用队列带来了什么好处呢?
1、更低的耦合,下单操作和后续的通知、发货、凭证操作完全分开了,下单完毕后发送订单数据到队列就像发送一个事件,需要的地方订阅这个事件就可以了。
2、更好的性能,没有使用队列时,下单操作要一次执行下单、通知、发货、凭证等多个处理,耗时较长;同时可能因为某个调用服务不稳定,导致整个下单操作不稳定,甚至完全不可用;要对下单操作进行性能优化时,需要考虑的方面过多,不容易达成。
3、容错,对于瞬时的异常,比如网络抖动、磁盘IO打满,导致后续操作无法执行时,队列可以缓存这部分数据,直到程序恢复处理能力后继续处理。没有使用队列的时候,只能记个日志,人工处理。
可能的坑
说几句废话,有些坑是使用队列新引入的,有些坑本来一直就存在,有的坑可以解决,有的坑只能把危害尽量降低。
最终一致性
如果没有使用队列,可以通过本地事务,甚至分布式事务来保证数据的严格一致性。
这不能算一个坑,但是需要理解使用了队列后就是选择了最终一致性,尽管有些队列支持RPC调用,但本质上仍是最终一致性。
通知可能延迟了2秒,发货可能推迟了1分钟,凭证可能晚生成了10秒,这些应该都是可以接受的,因为对于用户最重要的下单成功了,至于后边相对不那么紧急的事慢慢搞就好了,当然也不能慢的超出人的正常认知,响应速度取决于这些操作的处理能力。
消息仍可能会丢
为了防止数据在发送队列时丢失而生产者却不知情的情况,很多的队列都提供了发送确认,只有发送者收到了发送确认,消息才算投递成功。
但丢失消息的情况不止这一种,假设队列服务正常,在下单完成,发送订单数据到队列之前,服务器断电了,消息就永远不可能发到队列了。

为了处理此类极端情况,可以采用的方案也有几个,比如:
- 将消息和下单放到一个数据库事务中,即使当时没能发送到队列,也能在检查未发送消息的时候补上这一条。
- 在所有事务执行前记录日志,在每个事务完成后记录日志,从故障恢复后检查未完成的事务,执行这些事务。
不过除非逼不得已,波斯码仍然不建议在系统开发之初就搞这个方案,复杂了。
重复消息
由于网络问题或者因程序内部异常中断,发送者不能确定消息是否发送成功时,可能就会再次发送。
如果业务严格限制数据只能处理一次,消费者应该有能力来处理这种重复,可能的解决方案:在数据表中增加一个已处理消息的标识,或者缓存最近处理过的消息进行判重。
不当消息
在不使用队列,多个操作在同一个进程内执行的情况下,不同的接口可能设计了不同的参数,程序编写者需要在调用接口时传递不同的数据,以满足接口的业务需求。这种惯性思维可能被带入使用队列的情况下,为不同的业务发送不同的数据到队列,消费者消费各自定制的数据。这种做法完全忽视了使用队列进行解耦的好处。
应该把发送到队列的数据看作一个消息、或者一个事件,而不是某个具体业务方需要的某几个数据,这个消息可能是和业务方需求的数据完全吻合,也可能少或者多,对于业务方需要的缺少的数据应该可以根据消息中某个标识去查询,这样才算比较合适的解耦。
比如例子中发送下单成功的通知,需要订单金额和用户手机号,从队列接收到的是订单数据,其中有订单金额,没有手机号,但是有用户Id,程序需要根据用户Id去查询用户的手机号。
不当分发
在这篇文章举的例子中可以使用广播或者主题的分发方式,一条消息分发到多个消费者队列,每个消费者消费的消息互相之间没有影响。
在使用队列时需要特别关注分发方式,避免消息发送到了不需要的消费者队列,导致消费者因无法处理而崩溃;或者不同的业务消费同一个消费者队列,导致消息丢失业务处理。
不当高可用
每种队列产品都提供了高可用的解决方案,我们一般都会在生产环境采用高可用部署。
在实施高可用方案时应该清醒的认识到,可用性越高,就要在性能或一致性上有些损失,需要按照业务需求平衡这些指标。
选择队列产品
市面上常见的队列也不少,RabbitMQ、RocketMQ、Kafka、ActiveMQ、MetaMQ,甚至Redis也可以干这件事。网上有大量的文章介绍他们的原理和使用,这里也不过多的进行说明了。
说一下波斯码认为的主要三个:RabittMQ、RocketMQ、Kafka。
RabittMQ 社区活跃、管理界面易用、各种开发语言支持的比较好,单机万级别并发,适合中小型公司。
Kafka 为处理日志而生,吞吐量单机十万级,社区也很活跃。
RocketMQ 基于Kafka衍生而来,既保持了原有的高并发支持,又在可靠性、稳定性上得到了加持。阿里开源,社区活跃度一般,适合大公司。
发表评论
相关文章
国内AI资源汇总,AI聊天、AI绘画、AI写作、AI视频、AI设计、AI编程、AI音乐等,国内顺畅访问,无需科学上网。
扫码或点击进入:萤火AI大全
文章分类
最新评论