看到一句话很赞同:“没有评测就是猜测”,确实很多情况下都是如此,特别是不明白内部实现原理的时候。
今天突然想测试下Dictionary设置初始元素数会不会提升性能,因为设置capacity可以避免一定程度的resize,但究竟会怎样呢?
这里使用了老赵写的一个性能计数器,简单准确,比StopWatch更精确些。
第1个测试
下边是测试代码,Dictionary中key为int类型、value为string类型,基于100000数据,采用capacity初始化的实例和未采用capacity初始化的实例分别循环添加这些数据。
string[] source = new string[100000];
Random rand = new Random();
string seedStr = "abcdefghijklmnopqrstuvwxyzxyztysqwsxcdefrgvbtyhnujmikasdffddqasdfghjkuytbrveccwxzqe";
for (int i = 0; i < 100000; i++)
{
source[i] = seedStr.Substring(0, rand.Next(10, seedStr.Length));
}
CodeTimer.Time("Dictionary1", 1, () =>
{
Dictionary<int, string> dic = new Dictionary<int, string>(100000);
for (int i = 0; i < 100000; i++)
{
dic.Add(i, source[i]);
}
});
CodeTimer.Time("Dictionary2", 1, () =>
{
Dictionary<int, string> dic = new Dictionary<int, string>();
for (int i = 0; i < 100000; i++)
{
dic.Add(i, source[i]);
}
});
Console.ReadLine();
测试结果,采用capacity初始化的效果还是挺明显的,执行时间大约为未采用capacity实例的一半,CPU时钟周期大约为未采用capacity实例的一半,也没有产生垃圾回收。
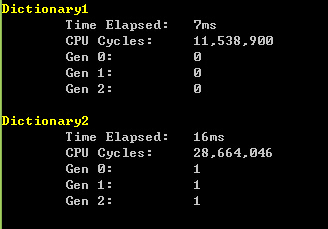
但是把数据量缩小到30000,执行时间在毫秒级上没什么差别了,但是CPU时钟周期还是接近一半的.
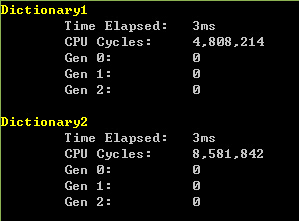
从这几个测试结果看,如果数据量不大,一般系统使用花费的时间没什么差别,即使把数据扩大到百万,相差也只在几十毫秒。
第2个测试
在上边的例子中采用int类型作为key,如果换成string会怎么样呢?
同样先看一个10000数据的例子,key采用 “n_”+i 得出:
string[] source = new string[1000000];
Random rand = new Random();
string seedStr = "abcdefghijklmnopqrstuvwxyzxyztysqwsxcdefrgvbtyhnujmikasdffddqasdfghjkuytbrveccwxzqe";
for (int i = 0; i < 1000000; i++)
{
source[i] = seedStr.Substring(0, rand.Next(10, seedStr.Length));
}
CodeTimer.Time("Dictionary1", 1, () =>
{
Dictionary<string, string> dic = new Dictionary<string, string>(100000);
for (int i = 0; i < 100000; i++)
{
dic.Add("n_" + i, source[i]);
}
});
CodeTimer.Time("Dictionary2", 1, () =>
{
Dictionary<string, string> dic = new Dictionary<string, string>();
for (int i = 0; i < 100000; i++)
{
dic.Add("n_" + i, source[i]);
}
});
测试结果,采用capacity初始化的Dictionary执行时间比int类型key时增长了接近10倍,但未采用capacity初始化的Dictionary则没有这么大的变化,CPU执行周期的比例也变的更小了。

把数据分别缩小到1W和增长到100W:
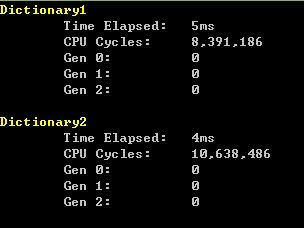

在1W数据的情况下,甚至出现了采用capacity的Dictionary执行的时间更长的情况,但是考虑到1ms的差距,这里认为所用时间是差不多的,在数据量变大的情况下,可以看到总体上采用capacity的Dictionary处理的开销更小,差距的绝对值也在变大,但是比例在缩小。
相比于int类型key,string类型key的Dictionary需要进行占用更多的CPU时钟周期,花费更多的处理时间,接近增长了一个数量级,并且那么时间去哪儿了呢?
答案是根据key获取hashcode,int比string更有效率。可以看这篇文章关于O(1)时间复杂度的问题。
总结下:
1、对于少量数据(可能不同场景少量对应的数量会不同)处理,或性能要求不是特别高的情况下,不采用capacity进行初始化问题也不大;当然如果能确定将要装载的数量,进行capacity初始化是一个更好的选择。
2、Dictionary中的key采用int、普通类型、数组其性能会更高些;采用字符串的话,字符串越长其性能越低。
这两点编码时需要综合考虑,并最好进行一些测试。
关键字: Dictionary
发表评论
相关文章
国内AI资源汇总,AI聊天、AI绘画、AI写作、AI视频、AI设计、AI编程、AI音乐等,国内顺畅访问,无需科学上网。
扫码或点击进入:萤火AI大全
文章分类
最新评论