在分布式系统中,特别是最近很火的微服务架构下,有没有或者能不能总结出一个业务静态数据的通用缓存处理机制或方案,这篇文章将结合一些实际的研发经验,尝试理清其中存在的关键问题以及探寻通用的解决之道。
什么是静态数据
这里静态数据是指不经常发生变化或者变化频率比较低的数据,比如车型库、用户基本信息、车辆基本信息等,车型库这种可能每个月会更新一次,用户和车辆基本信息的变化来源于用户注册、修改,这个操作的频率相对也是比较低的。
另外这类数据的另一个特点是要求准确率和实时性都比较高,不能出现丢失、错误,以及过长时间的陈旧读。
具体是不是应该归类为静态数据要看具体的业务,以及对变化频率高低的划分标准。在这里的业务定义中,上边这几类数据都归为静态数据。
为什么需要缓存
在面向用户或车联网的业务场景中,车型信息、用户基本信息和车辆基本信息有着广泛而高频的业务需求,很多数据都需要对其进行关联处理。在这里缓存的目的就是为了提高数据查询效率。静态数据通常都保存在关系型数据库中,这类数据库的IO效率普遍不高,应对高并发的查询往往捉襟见肘。使用缓存可以极大的提升读操作的吞吐量,特别是KV类的缓存,没有复杂的关系操作,时间复杂度一般都在O(1)。注意这里说的缓存指内存缓存。
当然除了使用缓存,还可以通过其它手段来提高IO吞吐量,比如读写分离,分库分表,但是这类面向关系型数据库的方案更倾向于同时提高读写效率,对于单纯提升读吞吐量的需求,这类方案不够彻底,不能在有限的资源情况下发挥更好的作用。
通用缓存机制
下面将直接给出一个我认为的通用处理机制,然后会对其进行分析。
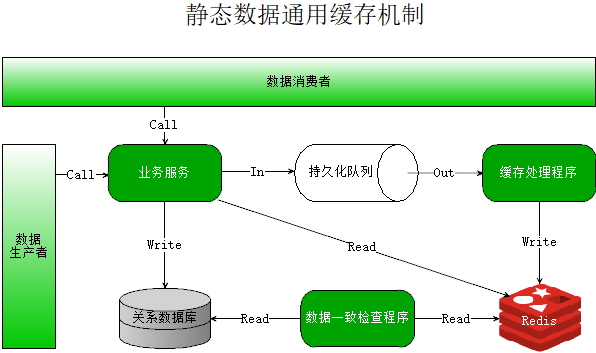
对于某个具体的业务,其涉及到六个核心程序:
-
业务服务:提供对某种业务数据的操作接口,比如车辆服务,提供对车辆基本信息的增删改查服务。
-
关系数据库:使用若干表持久化业务数据,比如SQLServer、MySQL、Oracle等。
-
持久化队列:可独立部署的队列程序,支持数据持久化,比如RabbitMQ、RocketMQ、Kafka等。
-
缓存处理程序:从队列接收数据,然后写入缓存。
-
数据一致处理程序:负责检查缓存数据库和关系型数据库中数据是否一致,如果不一致则使用关系数据库进行更新。
-
缓存数据库(Redis):支持持久化的缓存数据库,这里直接选了Redis,这个基本是业界标准了。
以及两个外部定义:
-
数据生产者:业务静态数据的来源,可以理解为前端APP、Web系统的某个功能或者模块。
-
数据消费者:需要使用这些业务静态数据的服务或者系统,比如报警系统需要获取车辆对应的用户信息以便发送报警。
下面以问答的形式来说明为什么是这样一种机制。
为什么需要业务服务?
既然是微服务架构,当然离不开服务了,因为这里探讨的是业务静态数据,所以是业务服务。不过为了更好的理解,这里还是简单说下服务出现的原因。
当今业务往往需要在多个终端进行使用,比如PC、手机、平板等,既有网页的形式,又有APP的形式,另外某个数据可能在多种不同的业务被需要,如果将数据操作分布在多个程序中很可能产生数据不一致的情况,另外代码不可避免的冗余,读写性能更很难控制,变更也基本上是不敢变的。通过一个业务服务可以将对业务数据的操作有序的管理起来,并通过接口的形式对外提供操作能力,代码不用冗余了,性能也好优化了,数据不一致也得到了一定的控制,编写上层应用的人也舒服了。
为什么不是进程内缓存?
很多开发语言都提供了进程内缓存的支持,即使没有提供直接操作缓存的包或库,也可以通过静态变量的方式来实现。对数据的查询请求直接在进程内存完成,效率可以说是杠杠滴了。但是进程内缓存存在两个问题:
-
缓存数据的大小:进程可以缓存数据的大小受限于系统可用内存,同时如果机器上部署了多个服务,某个服务使用了太多的内存,则可能会影响其它服务的正常访问,因此不适合大量数据的缓存。
-
缓存雪崩:缓存同时大量过期或者进程重启的情况下,可能产生大量的缓存穿透,过多的请求打到关系数据库上,可能导致关系数据库的崩溃,引发更大的不可用问题。
为什么是Redis?
Redis这类数据库可以解决进程内缓存的两个问题:
-
独立部署,不影响其它业务,还可以做集群,内存扩容比较方便。
-
支持数据持久化,即使Redis重启了,缓存的数据自身就可以很快恢复。
另外Redis提供了很好的读写性能,以及方便的水平扩容能力,还支持多种常用数据结构,使用起来比较方便,可以说是通用缓存首选。
为什么需要队列?
队列在这里的目的是为了解耦,坦白的说这个方案中可以没有队列,业务服务在关系数据库操作完成后,直接更新到缓存也是可以的。 之所以加上这个队列是由于当前的业务开发有很明显的系统拆分的需求,特别是在微服务架构下,为了降低服务之间的耦合,使用队列是个常用选择,在某些开发模型中也是很推崇的,比如Actor模型。
举个例子,比如新注册一个用户,需要赠送其300积分,同时还要给其发个注册成功的邮件,如果将注册用户、赠送积分、发成功邮件都写到一起执行,会产生两个问题:一是注册操作耗时增加,二是其中某个处理引发整体不可用的几率增大,三是程序的扩展性不好;通多引入队列,将注册信息分别发到积分队列和通知队列,然后由积分模块和通知模块分别处理,用户、积分、通知三个模块的耦合降低了,相互影响变小了,以后再增加注册后的其它处理也就是增加个队列的事,整体的扩展性得到了增强。
队列作为一种常用的解耦方案,在缓存这里虽然产生的影响不大,但是除了缓存难免同时还会有其它业务处理,所以为了统一处理机制,这里保留了下来。(既然用了,就把它发扬光大。)
为什么队列需要持久化?
持久化是为了解决网络抖动或者崩溃导致数据丢失的问题,在数据从业务服务到队列,队列自身处理,再从队列到缓存处理程序,中间都可能丢失数据。为了解决丢失数据的问题,需要发送时确认、队列自身持久化、接收时确认;但是需要注意确认机制可能会导致重复数据的产生,因为在未收到确认时就需要重新发送或接收,而数据实际上可能被正常处理,只是确认丢失了;确认机制还会降低队列的吞吐量,但是根据我们的定义业务静态数据的变更频率应该不高,如果同时还需要较高的并发分片是个不错的选择。
这里持久化队列推荐选择RabbitMQ,虽然吞吐量支持的不是很大,但是各方面综合不错,并发够用就好。
为什么需要数据一致检查程序?
在业务服务操作完关系数据库后,数据发送到队列之前(或者不用队列就是直接写入缓存之前),业务服务崩溃了,这时候数据就不能更新到缓存了。还有一种情况是Redis发生了故障转移,master中的更新没有同步到slaver。通过引入这么一个检查程序,定时的检查关系数据库数据和缓存数据的差别,如果缓存数据比较陈旧,则更新之。这样提供了一种极端情况下的挽救措施。
这个检查程序的运行频率需要综合考虑数据库压力和能够承受的数据陈旧时间,不能把数据库查死了,也不能陈旧太久导致大量数据不一致。可以通过设置上次检查时间点的方式,每次只检查从上次检查时间点(或者最近几次,防止Redis故障转移数据未同步的问题)到本次检查时间点发生变更的数据,这样每次检查只对增量变更,效率更高。
同时需要理解在分布式系统中,微服务架构下,数据不一致是经常出现的,必须在一致性和可用性之间做出权衡,尽力去降低影响,比如使用准实时或最终一致性。
只要数据一致检查程序是不是就够了?
假设没有缓存处理程序,通过定时同步关系数据库和缓存数据库是不是就够了呢?这还是取决于业务,如果是车型库这种数据,增加一个新的车型,本来之前就没有,时间上并不是很敏感,这个是可以的。但是对于新增了用户或者车辆,数据消费者还是希望能够马上使用最新的数据进行处理,越快越好,这时使用同步或者准同步更新就能更加贴近需求。
为什么不用缓存过期机制?
使用缓存过期机制可以不需要缓存处理程序和数据一致检查程序,业务服务首先从Redis查询数据,如果数据存在就直接返回,如果不存在则从关系数据库查询,然后写入Redis,然后再返回,这也是一种常用的缓存处理机制,网上可以查询到很多,很多人用的也很好。
但是缓存的过期时间是个问题:缓存多长时间过期,设置的短可以降低数据的陈旧,但是会增加缓存穿透的概率,即使采用随机的缓存过期时间,在Redis重启或者故障转移的情况下还是会可能导致缓存雪崩,雪崩的情况下采用数据预热机制,也可能会导致服务更长时间的不可用;设置的长可以提升缓存的使用率,但是增加了数据陈旧,在上边对静态数据的定义中对其准确率和实时性都有较高的要求,业务上能不能接受需要考虑。而且如果操作数据和查询存在波动的峰谷,是不是要引入动态TTL的机制,以达到缓存使用和直接访问数据库的一种平衡,这就需要权衡业务需求和技术方案。
总结
通过上边的这些问题问答,再来看看上面提出的微服务架构下静态数据通用缓存处理机制。
- 通过业务服务来包装对数据的操作,不管是操作关系数据库还是缓存数据库,数据消费者其实不需要关心,它只关心业务服务能不能提供高并发实时数据的查询能力。
- 利用分布式系统中经常使用队列进行解耦的方式,业务服务不干写入缓存的事,增加一个队列订阅数据变更,然后从队列取数据写入缓存数据库。
- 对于绝大部分正常的情况,通过队列更新缓存数据和业务服务中更新缓存数据,其实时性是差不多的,同时实现了业务操作和写缓存的解耦。
- 在极端崩溃导致数据不一致的情况下,通过数据一致检查程序进行补救,尽快更新缓存数据。
- 现在业务服务可以通过访问Redis缓存来提供对静态数据的高并发准实时查询能力,缓存中不存在的数据就是不存在,没有缓存穿透。
对于微服务架构而言,这个机制借助队列这种通用的解耦方式,独立了缓存更新处理,通过准实时更新和定时检查,保证了缓存的实时性和极端情况下较短时间内达到最终一致,通过缓存的持久化机制消除了缓存穿透和雪崩,在缓存的数据较大或读取并发较高时支持水平扩容,可以认为对业务静态数据提供了一种广泛适用的缓存处理机制。
这个方案在某些情况下可能是没有必要的,比如你要缓存一个全国限行的城市列表,使用一个进程内缓存就够了。
最后剩下的就是工作量的问题了,这个会给开发和维护带来复杂性,队列有没有用的顺手的,人手是不是够,业务需求是什么样的,需要考虑清楚。
后记
Redis耦合问题:图中业务服务直接访问了Redis,如果要实现业务服务对Redis的完全透明,这个还比较复杂,可以考虑采用AOP的方式,对关系数据库和Redis保持相同的类型定义,分别采用ORM和反序列化的方式标准化输出,这是个想法我也没有实现;同时缓存数据是准实时的,如果要求完全一致,还是应该提供从关系数据库查询的版本。另外如果要摆脱对Redis的直接依赖,还可以通过OpenResty来实现对资源的透明访问,这个不是本文的重点。
服务可用性问题:这篇文章没有关注服务可用性问题,为了保证服务的高可用,每个服务或者程序都应该有多份部署的,无论是负载均衡的方案,或者传统的主备方案,在部分部署不可用时仍能够继续提供服务。
写的比较快,有些理解不免偏颇,欢迎指正。
发表评论
相关文章
国内AI资源汇总,AI聊天、AI绘画、AI写作、AI视频、AI设计、AI编程、AI音乐等,国内顺畅访问,无需科学上网。
扫码或点击进入:萤火AI大全
文章分类
最新评论